
Boost SQL Server Performance: 20 Indexing Strategy Tips to Elevate Your Database
How can you achieve a 1,000% improvement in a crucial database process with just one modification, all while maintaining your application’s functionality? The key lies in crafting the perfect indexing strategy for your database. Performance tuning is vital for ensuring that your SQL Server-based applications run seamlessly and efficiently.
Among the most critical aspects of performance tuning is refining the indexing strategy. A well-thought-out indexing approach can lead to substantial performance enhancements, decreased execution times, and heightened system responsiveness. In this article, we’ll delve into how you can fine-tune your indexing strategy and unlock the full potential of your SQL Server with Fortified’s top 20 expert techniques for analyzing indexing strategies.
SQL Server Performance Tuning – Indexing Strategy Essentials
Before diving into the Top 20 techniques for examining data, let’s first review some crucial information about devising the ideal indexing strategy.
Comprehend the Significance of Indexes
Indexes are database objects that accelerate data retrieval from tables. They function similarly to a book’s index, enabling the database engine to swiftly locate the necessary data without scanning every row. However, a poorly designed or excessive number of indexes can cause performance issues and extended query times.
Tip: As a basic rule of thumb, a normalized table with a mix of reads and writes should have around 3 to 5 indexes per table. If a table has more than 75% reads, it can accommodate over 5 indexes per table since the indexes will not impact the performance from maintaining the write activity.
Select the Appropriate Index Type
SQL Server provides two main index types: clustered and non-clustered. Clustered indexes dictate the physical order of data in a table and can substantially enhance performance for range queries. However, each table can only have one clustered index.
Non-clustered indexes, separate from the data, allow multiple indexes per table but may be less efficient for extensive data scans. Choose the index type that best aligns with your application’s query patterns and data access requirements.
Exercise Caution with Index Creation
While creating multiple indexes on every table may seem appealing, doing so can lead to increased data addition or modification times, as well as higher storage and maintenance costs. Be judicious with your indexes, focusing on the columns and tables crucial to query performance. Examine your application’s query patterns and utilize tools like the SQL Server Profiler to identify the most frequently executed and resource-intensive queries.
Tip: Narrow indexes can support a larger number of queries compared to wider indexes with more columns.
Implement Covering Indexes
A covering index comprises all the columns needed to fulfill a specific query. By incorporating all required columns in the index, SQL Server can obtain the data directly from the index, eliminating the need to access the underlying table. This can result in a substantial performance improvement, especially for frequently executed queries.
Streamline Index Maintenance
Although indexes can significantly enhance query performance, they can also create overhead during data modification operations (inserts, updates, and deletes). Regular index maintenance, such as rebuilding or reorganizing indexes, can help maintain their efficiency and minimize performance impact. Utilize SQL Server’s built-in tools, like the Database Engine Tuning Advisor and dynamic management views, to monitor index fragmentation and establish the most effective maintenance strategy.
Employ Filtered Indexes
Filtered indexes are a type of non-clustered index that only includes rows meeting specific criteria. They are particularly useful for large tables with a small subset of frequently queried data. By generating a filtered index on the relevant subset, you can reduce index size, decrease maintenance overhead, and enhance query performance.
Sustain the Ideal Indexing Strategy
Consistently monitoring your SQL Server’s performance and index usage is crucial for upholding an optimized indexing strategy. Every quarter or so, allocate time to optimize the indexing strategy by identifying tables with increased data volume or where new system functionality has altered table access patterns.
SQL Server Performance Tuning – Building the Indexing Strategy
Armed with the essential background on indexes, let’s explore how to pinpoint potential indexes for optimizing a database. It’s crucial to understand that developing and refining the indexing strategy is an iterative process. This is due to the ever-growing number of tables requiring optimization across the enterprise, as well as the constant influx of code changes and data growth affecting the indexing strategy. Nonetheless, Fortified believes that this is among the most vital tasks a DBA should prioritize, besides safeguarding and managing data.
Before identifying any indexes, we must take advantage of SQL Server’s robust utilization and metadata features, which offer insights into system utilization and configuration of the indexes. Fortified harnesses system tables and the sys.dm_db_index_usage_stats DMV to analyze usage data.
An index script employed by Fortified is used to assess the data and will be demonstrated in the examples below. The objective is to run this script on a SQL Server and transfer the data to Excel with the top row filtered.
Tip: As the DMV relies on data from the last SQL Server restart, ensure that there is at least a couple of weeks’ worth of data or more so that the business processes are accurately represented in the data.
The Top 20 techniques for optimizing the indexing strategy are outlined below, accompanied by an example for each method.
1. Unused Indexes – Open the Custom Sort and arrange the columns to display tables with the highest number of updates on objects that have not been queried. Fortified recommends considering the disabling of these indexes, which can be re-enabled if necessary.
-- UNUSED INDEXES WHERE IsUnique = 0 AND IndexID > 0 AND [UserSeeks] = 0 AND [UserScans] = 0 AND [UserLookups] = 0 ORDER BY [UserUpdates] DESC
2. Heaps (Tables without Clustered Indexes) – While there may be some disagreement, Fortified generally believes that every table should have a clustered index to optimize performance and maintenance. Objects with more than 25% updates should have clustered indexes, as HEAPs maintain forward pointers to the active data page, which can negatively impact performance over time.
-- HEAPS WITH HIGHEST UPDATES AT THE TOP WHERE [Disabled] = 0 AND IndexID = 0 ORDER BY [UserUpdates] DESC
3. Duplicate indexes – Duplicate indexes may seem obvious, but with many developers and DBAs adding indexes over time, the chances of duplicate indexes on tables increase. Use the “Indexes – Duplicates.sql” to identify duplicate or overlapping indexes.
4. Overlapping Indexes – Similar to duplicate indexes, developers and DBAs add indexes over time to optimize specific queries. To identify overlapping indexes, sort by database name, table name, and column name to review the indexes. Indexes with the same columns, those that use INCLUDED columns, or a different order can qualify as overlapping indexes.
The goal is to determine which index has the higher Index Seeks and potentially add a column to the other index in the includes. This allows you to DROP or DISABLE the other indexes. Use the “Indexes – Duplicates.sql” to identify duplicate or overlapping indexes.
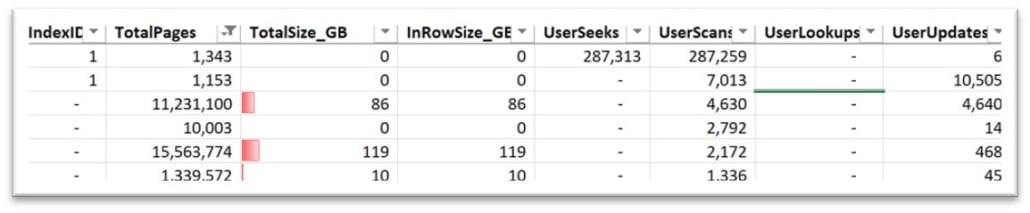
5. Large Tables with a High Scan Count – Identifying the largest tables with higher table scans is an efficient way to reduce the physical resources SQL Server uses for both memory and IOPS. First, filter tables with more than 1,000 data pages or a number where SQL Server is not scanning the entire table because it is more efficient.
-- LARGE TABLES WITH A HIGH SCAN COUNT AND FEWER INDEXES WHERE [Disabled] = 0 AND TotalPages > 1000 AND [COUNT] < 3 ORDER BY [UserScans] DESC, TotalPages DESC
In the image below, there are tables that are 86GB and 119GB in size being scanned 4,630 and 2,172 times, respectively. Every time one of these indexes are scanned, memory is potentially flushed to free up space, and the number of IOPS increases as it has to return a significant amount of data.
6. High Lookups – A table with a high number of lookups indicates that existing indexes could benefit from adding one or more additional columns to the index. As mentioned earlier, a narrow index can be used by more indexes, but a very high number of lookups is costly for highly transactional objects. The goal is to identify the indexes with the highest number of lookups, pinpoint the missing columns, and potentially add them as INCLUDED columns in the index.
-- HIGH LOOKUPS WHERE [Disabled] = 0 ORDER BY USERLOOKUPS DESC
7. Table with a Low Number of Indexes – To identify indexes that can be easily added to improve performance, filter tables that only have one or two indexes, as this will display all the tables that have minimal indexes. Typically, a table has 3-5 indexes depending on the level of normalization and activity on the table. By filtering tables with one to two indexes, you can quickly identify indexes with a higher number of User Scans, indicating that there is no index SQL Server can use to retrieve the data faster.
-- TABLE WITH A LOW NUMBER OF INDEXES WHERE [Disabled] = 0 AND [COUNT] <= 2 AND TotalPages > 1000 ORDER BY UserScans DESC
8. Wide Clustered Indexes – Clustered indexes are part of every non-clustered index and should be as narrow as possible. If you have tables with composite indexes (indexes with more than one column) that are not unique, consider creating a surrogate key. A surrogate key is an artificial unique key assigned to each record. Using a surrogate key reduces space, and if it’s an integer, SQL Server will process it faster.
9. Cost Benefit is Low – Indexes that are not used as frequently but have a higher number of INSERT, UPDATE, or DELETE operations can be considered costly. If an index has a lower number of index seeks and scans compared to the number of index updates, it has a lower cost-benefit. To identify costly indexes, execute the following script – “Indexes – Costly.sql”.
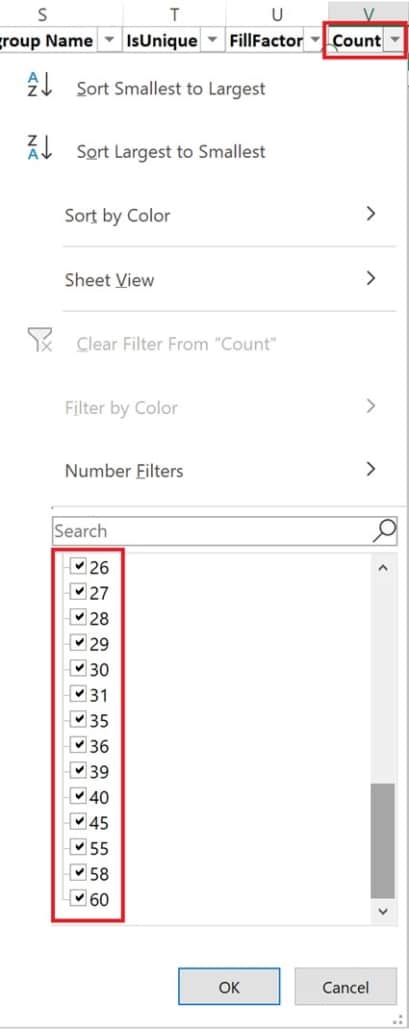
10. Over Indexed Table – Each time SQL Server modifies data within a table, it updates all the table’s indexes, increasing the transaction time. Tables with five or more indexes in a transactional system are potential candidates for reducing the number of indexes they have. Before disabling all indexes, review the % Read and % Write columns.
For tables with a higher read percentage, the system can have a greater number of indexes to support different access paths. However, for tables with a higher write percentage, aim for three to five indexes for each table. In the image below, notice that some tables have up to 60 indexes on a single table. Imagine the amount of work SQL Server has to do for each update on this table.
11. Non-Unique Clustered Indexes – A non-unique clustered index adds a uniqueifier which increases the size of the clustered index. To optimize the storage and performance, consider creating a surrogate key. A surrogate key is an artificial unique key which can be assigned to each record. By using a surrogate key, it reduces space and if it is an integer, SQL Server will process that faster.
12. Low Number of INCLUDEs Usage – Often, a legacy application’s indexing strategy works well but hasn’t been optimized for years and doesn’t take advantage of newer SQL Server features like INCLUDED columns. INCLUDED columns allow an index to contain all columns between the indexed values and INCLUDED values, satisfying queries, and reducing the number of index lookups. For indexes with a higher number of lookups or wide non-clustered indexes, consider adding relevant columns to be included.
13. Non-Compressed Indexes – Data compression is another way to enhance index and system performance. SQL Server offers ROW and PAGE compression, which compress data in memory and on disk, increasing memory density and reducing IOPS. Some may question the performance overhead; however, if you apply the methodology below, it won’t add any overhead to the system and often reduces resource usage. Apply these rules to each object:
• Wave 1 – Objects with 75% or more reads – PAGE Compress
• Wave 2 – Objects with 25% or more writes – ROW Compress
NOTE: Start slow if you’re unsure and apply to low-usage objects that are primarily read-only. Overhead primarily affects write-intensive objects, and if you can compress 90% of the objects, the overall resource gains are significant.
14. Disabled Indexes – Sometimes, when reviewing a system’s indexing strategy, you may find DISABLED indexes. To identify them, filter on Disabled = 1. While they don’t take up storage or impact performance, periodically dropping disabled indexes after a couple of months is recommended. If you’re supporting a third-party application, consider keeping them just in case they’re needed for upgrades or support.
15. Hypothetical Indexes – If you’ve ever run Index Tuning Advisor, you might have some hypothetical indexes in the system. Like disabled indexes, consider dropping them after testing the indexes. To identify them, filter on Hypothetical = 1.
16. Contentious Indexes – Indexes often contribute to performance, but sometimes we need to optimize them on a table to reduce blocking or deadlocks. When you identify a unique blocking or deadlock chain that’s escalating the lock level or requires data updates, consider altering the table’s indexing strategy. Often, solving blocking and deadlock chains involves adding or altering an existing index, ultimately optimizing the query’s access path.
17. Non-Index Foreign Keys – Foreign key constraints represent relationships between two tables on specific columns, enabling SQL Server to validate the data’s existence in the parent and child tables. By default, SQL Server doesn’t create an index on each foreign key; however, if the code is joining tables on these columns, consider adding an index based on the query predicate and execution plan. Not all foreign keys need indexes, but for those with a higher number of references in the code, add a non-clustered index on the column.
18. Low FILLFACTOR – Low FILLFACTOR – FILLFACTOR determines how full data pages should be. The default is 100%, and for most systems, the DEFAULT works for the majority of objects. However, there are a few important considerations:
• Clustered Indexes with IDENTITY – In SQL Server, indexes are balanced B-Trees, and since an IDENTITY value continuously increases, it always adds data to the end. As a result, you should not set the FILL FACTOR below 100, or you’ll waste space on each data page.
• The lower the FILL FACTOR, the more free space available on each data page. For larger indexes of 1GB and above, this free space affects memory and the number of IOPS needed to retrieve data pages. It is recommended to keep the default and only lower the FILL FACTOR for highly volatile objects.
For example, consider an index that is 50GB in size and has a FILL FACTOR of 50%. This means the data in the index could be stored in 25GB, but the likelihood of new data being evenly added to each data page across the table is low. Hence, it is recommended to keep the FILL FACTOR at or above 90%.
NOTE: Fragmentation is less of an issue today due to faster storage subsystems. Although fragmentation increases the number of pages to be returned, most application queries won’t notice the millisecond differences in runtime unless the database objects are very large and fragmentation is 50% or less.
19. Page Splits – Indexes with a higher number of INSERTs over time may experience more page splits. While page splits are natural database activities, like locking and blocking, the goal is to minimize them when possible. To reduce page splits, consider decreasing the FILL FACTOR on the index to 90% and implementing a dynamic index rebuild process that runs nightly to rebuild indexes with higher fragmentation levels.
20. Non-Optimal Clustered Indexes – Sometimes, application or database developers design schemas and add indexes based on the assumption that code will utilize these indexes. However, there are instances where the clustered index has a low number of Index Seeks and a high number of User Lookups, while another non-clustered index has a high number of Index Seeks.
In these cases, the non-clustered index would be a better clustered index because the code uses the index key to seek data. For highly transactional tables, swapping the non-clustered index to a clustered index can significantly reduce CPU usage by decreasing the number of lookups on the system.
Optimization should be part of your Run the Business
Optimization should be part of your business operations. Optimizing your indexing strategy is a crucial aspect of SQL Server performance tuning and should be prioritized. Understanding the importance of optimizing database platforms and the critical role of indexes will enable businesses to reduce costs while enhancing application performance. This becomes increasingly important as data creation and acquisition rates grow, and database platforms migrate to the cloud, where each resource potentially incurs costs.
If you are seeking experts to partner with you in your SQL Server performance tuning, than look no further than Fortified’s team of expert DBAs. Whether you are seeking full 24/7 Database Managed Services or Performance Tuning Consulting Services, our team is here to help with your immediate and long-term needs.
Connect with our sales team today to discover how Fortified can help you.
Leave a Reply
Want to join the discussion?Feel free to contribute!